Post
서버 이중화
회사 시스템을 이용하면서 큰 트래픽을 잡아먹는 시스템이 아니기 때문에, 이중화가 안된 부분이 너무 많아 참고하기 위해 작성했습니다.
현재는 빌드된 부분을 적용하려면 모두 서비스를 중단해야 하는 방식 입니다. 이걸 배제하기 위해 로직 처리를 프론트단, DB단 프로시저를 많이 이용하게 되는데 앞으로는 이중화에 대한 고민이 필요해 보인다
이중화 (Duplication, Duplex)
이중화는 말 그대로 장비를 두개 놓는것
- 운영중인 서비스의 안정성을 위해서 하드웨어,OS,미들웨어,DB 등을 여러개로 구성
- 장비의 성능을 끌어올리기 위해
- 서비스의 지속성을 보장하기 위해
=> 한쪽 장비 다운 시 반대쪽 장비에서 서비스하기 위함
일반적으로 하나의 요소에 오류가 발생하더라도 중복된 다른 요소가 이를 대체하여 서비스를 계속 유지시키는 이중화 방식을 채택
이중화 방식은 어느 한 쪽만이 동작하다가 장애 발생 시 다른 한 쪽이 동작을 이어감
-> Active-Standby 이중화와 Active-Active 이중화 방식
FailOver
FailOver가 이중화와 같은 개념
FailOver는 평소에 사용하는 서버와 그 서버의 클론 서버를 가지고 있다가 사용 서버가 장애로 사용이 어렵게 되었을 경우 클론 서버로 그 일을 대신 처리하게 해서 무정지 시스템을 구축하게 해 주는 것을 의미
LoadBalancing
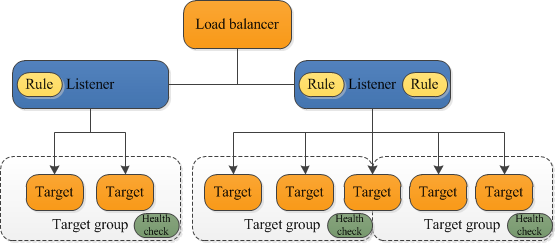
- L4 장비 담당
-> L4스위치는 로드밸런싱을 하는 장비이고 외부에서 들어오는 모든 요청은 L4스위치를 거칩니다.
-> L4장비는 트래픽의 부하를 보고 자신과 연결된 서버에게 부하분산 서비스를 제공
-> 회선 이중화를 통하여 한쪽 회선에 많은 트래픽이 흐를 경우 반대쪽 회선에 트래픽을 보내주는 부하분산 역할을 수행
- LoadBalance란 두 개 이상의 서버가 일을 분담처리해 서버에 가해지는 부하를 분산시켜 주는 것
- > 여러 대의 처리기-서버가 병렬로 작업을 처리하도록 하여 서버의 부하를 균형 있게 잡아줌
=> 한 처리기에 너무 많은 부하가 걸리거나 너무 적게 걸려 낭비되지 않도록 작업을 적절히 분배하고, 필요한 경우에는 작업을 한 처리기에서 다른 처리기로 이동시킴
보통은 사용자가 처리기-서버에 부하가 걸릴만한 상황을 고려하여 조건을 설정하고 조건이 충족된 상황에서 다른 서버가 일을 분담 처리
*L4 vs L7
L4는 부하만 분산시키지만, L7은 요청의 세부사항을 두고, 결재,회원 등 세부적인 사항을 두고 각각의 서비스를 여러개로 운용하면서 작은단위에서의 요청을 서버에 분산하는 방식으로, 더 업그레이드된 방식이지만 자원소모가 큼

서버 이중화
- 서버 인프라 설계 및 운영시 서비스의 안정적인 운영을 위해 서버 이중화를 구성
- 서버 이중화는 물리적 또는 논리적인 서버(또는 LAPR) 등을 구성하여 하나의 서비스에 장애가 발생하는 경우 다른 서버를 통해 서비스를 지속가능
- 서버 이중화 또는 다중화란 운영중인 서비스의 안정성을 위하여 각종 자원(전기, 서버기기, OS, 미들웨어, DB 등)을 이중또는 그 이상으로 구성하는 것
-> 이러한 구성은 HA(high Availability) 서비스와 디스크 RAID 구성, 오라클의 RAC(real Application Clusters) 등 으로 구현
서버 이중화 목적
1. (Failover) 장애 또는 재해시 빠른 서비스 재개를 위함
- 하드웨어, 미들웨어 등 다양한 지점에서 오류가 발생할 수 있으며 사용자가 이를 인지하지 못하도록 하기 위함
- 서비스의 일시적인 중단이 발생하더라도(다운타임 발생하더라도) 재빠르게 대응 가능
-> 대응 과정은 예측 가능 시 1차적으로 자동으로 Failover 할 수 있도록 설계
2. (로드밸런싱_Load balancing, 부하분산) 원활한 서비스의 성능을 보장 하기 위함
- 하나의 기기에서 일정량 이상의 사용자 트랜잭션을 처리하는 경우 응답시간이 느려질 가능성 있음
- 사용 트랜잭션의 패턴과 사용량 등을 분석하여 부하를 분산하여 효율적인 업무처리가 가능
-> 로드밸런싱은 구현하고자 하는 지점에 따라 미들웨어, 네트워크, OS 등 다양한 지점에서 구현가능
서버 이중화 방법
보통 서버 이중화를 구성은 Active-Active / Active-Standby 으로 구현
- Active-Active 구성은 부하분산 등의 목적으로 주로 활용, 서비스 단위를 나누어서 분산
- Active-Stand by 구성의 경우에는 즉각적인 Failover를 위해 구성
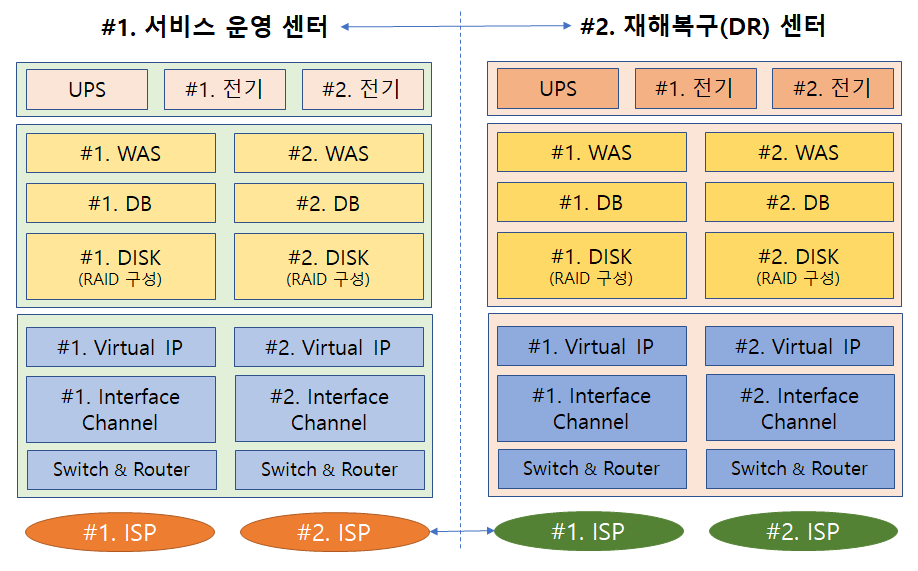
서버 이중화 구성도
Active-Active
- L4 스위치 등의 부하분산(SLB) 로드밸런싱을 통해 기능 또는 성격 등에 따라 1번 또는 2번 서버로 나누어서 처리하도록 구성
- 웹 서버 이후에 데이터베이스 서버에 접근이 필요한 경우에도 2개 이상의 서버를 둠
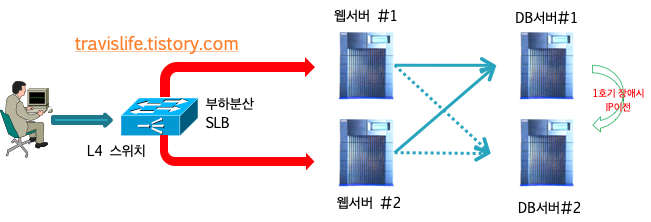
서버이중화 : Active-Active 구조
- 대부분 웹서버는 L4 스위치 SLB(Server Load Balancing)으로 구성하고 DB서버는 Oracle RAC(Real Application Cluster)를 활용
- 디스크 공유도 마찬가지인데 Veritas CFS(Cluster File System) 등으로 구성할 수 있다. 이러한 구성은 특정기기 장애시 1번 또는 2번 서버등으로 서비스를 지속 운영할 수 있다는 장점이 있고 Down Time이 존재하지 않음
Active-Standby
- Active-Standby 구조는 서버를 이중화하여 구성하지만 동시에 부하분산을 통해 모든 기기에서 서비스하는 것이 아니라 장애시에 서비스를 이전하여 운영하는 형태로 구성된 것을 의미
- 흔히 운영시스템이라고 부르는 운영시스템 서버(메인 서버)가 장애시 서비스 장애를 즉시 인지하여 서브 서버로 서비스를 이전.
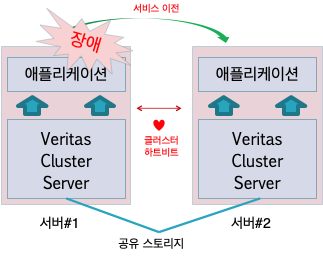
서버이중화 : Active - Stand By 구조
- 이러한 과정은 클러스터 하트비트(Heart) 등으로 시스템의 정상상태를 주기적으로 체킹하고 특이사항이 발생하는 경우 시스템 엔지니어의 의사결정을 통해 수동으로 서브 서버로 서비스를 전환하거나, 크리티컬한 장애시 자동으로 서비스를 전환
-> 불가피한 장애에 대비하는 것이며 서비스의 다운타임을 최소화시키고자 함
Master-Slave 구조
이번엔 조금 다른 개념으로 넘어왔다.
Master 서버의 기준은 CUD가 가능하다는 것이다. 그에 비해, Slave 서버는 Read가 가능하다.
역할이 달라지는 것이며, 그에 따라 트래픽이 분산될 수 있다.
Master는 데이터 동시성이 아주 높은 트랜잭션을 담당하고, Slave는 데이터 동시성이 꼭 필요없는 경우에 읽기 전용으로 데이터를 가져온다.
Master가 Slave에게 데이터를 알려주는 구조는 다음과 같다.
- Master DB에 Data가 변경될 시, Master DB에 반영
- 변경 이력을 Binary Log로 저장
- Slave DB에게 이벤트 전송
- Slave IO Thread에서 이벤트를 받고, Binary Log를 Slave DB 각각의 Relay Log에 저장
- Slave SQL Thread에서 Relay Log를 읽어 Slave DB 업데이트
- 읽기 처리 시, Slave DB를 사용
다만, 데이터가 들어오는 양이 많아진다면, Master가 Slave에게 알려주기 전에 SELECT 요청이 들어올 수 있다.
이를 복제 지연이라고 하며, 이럴 때는 임시로 Master에게도 Select Query가 가능하도록 만들어 주기도 한다.
참고자료
https://velog.io/@cyseok123/AWS-EC2-HTTPS-%EB%A1%9C%EB%93%9C%EB%B2%A8%EB%9F%B0%EC%84%9C
https://blog.naver.com/cometrue0319/222409964758
댓글